- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
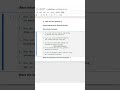
Python Interview Questions: Polars, DuckDB, PyCaret, Kedro & Ray! 🚀 #Python #DataScience #BigData
1️⃣ Polars for High-Performance DataFrames
Polars is a DataFrame library written in Rust with a Python API, offering lightning-fast operations and lazy evaluation.
Unlike pandas, it uses Arrow memory format and supports multi-threaded execution.
Example:
import polars as pl
df = pl.read_csv("large.csv")
result = df.groupby("category").agg(pl.col("sales").mean())
print(result)
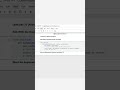
2️⃣ DuckDB for In-Process Analytics
DuckDB is an embedded OLAP database, designed for analytical queries directly from Python, R, or command line.
Think of it as SQLite but optimized for analytics.
Example:
import duckdb
con = duckdb.connect()
df = con.execute("SELECT category, AVG(price) FROM 'large.csv' GROUP BY category").df()
print(df)
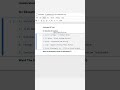
3️⃣ PyCaret for Low-Code Machine Learning
PyCaret automates the ML workflow: preprocessing, model training, tuning, and deployment.
Perfect for fast prototyping without writing long code.
Example:
from pycaret.classification import setup, compare_models
data = pd.read_csv("data.csv")
s = setup(data, target="label")
best_model = compare_models() # Auto-selects the best classifier
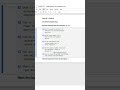
4️⃣ Kedro for Data Pipelines
Kedro is a Python framework for reproducible, modular data pipelines.
Encourages clean project structure with nodes (functions), pipelines, and configuration.
Example:
# node.py
def preprocess(data: pd.DataFrame) -v pd.DataFrame:
return data.dropna()
# pipeline
from kedro.pipeline import node, Pipeline
pipeline = Pipeline([node(preprocess, "raw_data", "clean_data")])
5️⃣ Ray for Distributed Data Science
Ray is a Python framework for parallel computing, scaling ML, DL, and reinforcement learning workloads.
Frameworks like Modin, RLlib, and Tune run on Ray.
Example:
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))
Видео Python Interview Questions: Polars, DuckDB, PyCaret, Kedro & Ray! 🚀 #Python #DataScience #BigData канала CodeVisium
Polars is a DataFrame library written in Rust with a Python API, offering lightning-fast operations and lazy evaluation.
Unlike pandas, it uses Arrow memory format and supports multi-threaded execution.
Example:
import polars as pl
df = pl.read_csv("large.csv")
result = df.groupby("category").agg(pl.col("sales").mean())
print(result)
2️⃣ DuckDB for In-Process Analytics
DuckDB is an embedded OLAP database, designed for analytical queries directly from Python, R, or command line.
Think of it as SQLite but optimized for analytics.
Example:
import duckdb
con = duckdb.connect()
df = con.execute("SELECT category, AVG(price) FROM 'large.csv' GROUP BY category").df()
print(df)
3️⃣ PyCaret for Low-Code Machine Learning
PyCaret automates the ML workflow: preprocessing, model training, tuning, and deployment.
Perfect for fast prototyping without writing long code.
Example:
from pycaret.classification import setup, compare_models
data = pd.read_csv("data.csv")
s = setup(data, target="label")
best_model = compare_models() # Auto-selects the best classifier
4️⃣ Kedro for Data Pipelines
Kedro is a Python framework for reproducible, modular data pipelines.
Encourages clean project structure with nodes (functions), pipelines, and configuration.
Example:
# node.py
def preprocess(data: pd.DataFrame) -v pd.DataFrame:
return data.dropna()
# pipeline
from kedro.pipeline import node, Pipeline
pipeline = Pipeline([node(preprocess, "raw_data", "clean_data")])
5️⃣ Ray for Distributed Data Science
Ray is a Python framework for parallel computing, scaling ML, DL, and reinforcement learning workloads.
Frameworks like Modin, RLlib, and Tune run on Ray.
Example:
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))
Видео Python Interview Questions: Polars, DuckDB, PyCaret, Kedro & Ray! 🚀 #Python #DataScience #BigData канала CodeVisium
Комментарии отсутствуют
Информация о видео
24 сентября 2025 г. 20:58:23
00:00:10
Другие видео канала