- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
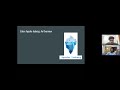
From CDC to Apache Iceberg in Minutes 🚀 | OLake + Trino Demo ft. Lester Martin (Starburst)
Modern data pipelines break at scale not because of tools, but because of complexity, fragmentation, and performance bottlenecks.
In this session, we show how to go from raw database changes to fully queryable Apache Iceberg tables using OLake and how to efficiently query and optimize them using Trino.
Huge thanks to Lester Martin (Developer Advocate at Starburst) for sharing deep insights into Iceberg internals, query performance, and the small file problem.
What we’ll cover:
1. High-throughput ingestion with Full Load + CDC using OLake
2. Iceberg fundamentals: metadata, snapshots, and file structure
3. The small file problem and its impact on performance
4. Querying Iceberg with Trino
5. Compaction and optimization for faster queries
The session includes a live demo of end-to-end data replication and query optimization, with practical insights for building scalable, open lakehouse pipelines.
OLake website - https://olake.io
OLake GitHub - https://github.com/datazip-inc/olake
Join OLake Slack - https://olake.io/slack
Find us on LinkedIn - https://www.linkedin.com/company/datazipio
Видео From CDC to Apache Iceberg in Minutes 🚀 | OLake + Trino Demo ft. Lester Martin (Starburst) канала OLake
In this session, we show how to go from raw database changes to fully queryable Apache Iceberg tables using OLake and how to efficiently query and optimize them using Trino.
Huge thanks to Lester Martin (Developer Advocate at Starburst) for sharing deep insights into Iceberg internals, query performance, and the small file problem.
What we’ll cover:
1. High-throughput ingestion with Full Load + CDC using OLake
2. Iceberg fundamentals: metadata, snapshots, and file structure
3. The small file problem and its impact on performance
4. Querying Iceberg with Trino
5. Compaction and optimization for faster queries
The session includes a live demo of end-to-end data replication and query optimization, with practical insights for building scalable, open lakehouse pipelines.
OLake website - https://olake.io
OLake GitHub - https://github.com/datazip-inc/olake
Join OLake Slack - https://olake.io/slack
Find us on LinkedIn - https://www.linkedin.com/company/datazipio
Видео From CDC to Apache Iceberg in Minutes 🚀 | OLake + Trino Demo ft. Lester Martin (Starburst) канала OLake
Комментарии отсутствуют
Информация о видео
6 апреля 2026 г. 11:02:26
00:43:13
Другие видео канала