- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
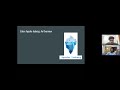
How to Maintain Apache Iceberg Tables — Monthly Webinar by OLake with Amit Gilad, CTO- Lakeops
We’re back with another monthly event by OLake!
This deep-dive covers Apache Iceberg table maintenance best practices to keep your lakehouse fast, cost-efficient, and production-ready.
Guest speaker Amit Gilad, CTO at LakeOps (8+ years in data systems and a frequent Apache Iceberg speaker), shares field-tested tactics for compaction, metadata hygiene, and file layout optimization the exact knobs that reduce scan size, improve pruning, and stabilize p95 query latency across engines like Spark Trino, Flink, DuckDB, and ClickHouse.
Here's what we deep dive into-
-Iceberg compaction strategies explained: bin-packing vs sort compaction vs Z-ordering—how to choose per workload, target file sizes (e.g., 256–512 MB), and when to re-write data files.
-Fixing the small-file problem on object storage (Amazon S3, Azure ADLS, Google Cloud Storage): fewer files, lower planning overhead, better parallelism.
-Snapshot management & metadata hygiene: safe snapshot expiration policies, orphan file cleanup, manifest & manifest-list rewrites to reduce planning time and metadata bloat.
-Partitioning & evolution: avoiding over/under-partitioning; how day→hour partition evolution + sort compaction boosts predicate pruning without exploding costs.
-And most importantly cost-vs-performance.
Who should watch
Data engineers, platform teams, architects, and technical leaders running production Apache Iceberg who want lower cloud bills and stable performance under growing data volumes.
#ApacheIceberg #dataengineering #Lakehouse #spark #Trino #flink #duckdb #clickhouse
OLake website - https://olake.io
OLake GitHub - https://github.com/datazip-inc/olake
Join OLake Slack - https://olake.io/slack
Find us on LinkedIn - https://www.linkedin.com/company/datazipio
➡ MongoDB to Apache Iceberg getting started - https://olake.io/docs/getting-started/mongodb
➡ MySQL to Apache Iceberg getting started -https://olake.io/docs/getting-started/mysql
➡ Postgres to Apache Iceberg getting started -https://olake.io/docs/getting-started/postgres
Видео How to Maintain Apache Iceberg Tables — Monthly Webinar by OLake with Amit Gilad, CTO- Lakeops канала OLake
This deep-dive covers Apache Iceberg table maintenance best practices to keep your lakehouse fast, cost-efficient, and production-ready.
Guest speaker Amit Gilad, CTO at LakeOps (8+ years in data systems and a frequent Apache Iceberg speaker), shares field-tested tactics for compaction, metadata hygiene, and file layout optimization the exact knobs that reduce scan size, improve pruning, and stabilize p95 query latency across engines like Spark Trino, Flink, DuckDB, and ClickHouse.
Here's what we deep dive into-
-Iceberg compaction strategies explained: bin-packing vs sort compaction vs Z-ordering—how to choose per workload, target file sizes (e.g., 256–512 MB), and when to re-write data files.
-Fixing the small-file problem on object storage (Amazon S3, Azure ADLS, Google Cloud Storage): fewer files, lower planning overhead, better parallelism.
-Snapshot management & metadata hygiene: safe snapshot expiration policies, orphan file cleanup, manifest & manifest-list rewrites to reduce planning time and metadata bloat.
-Partitioning & evolution: avoiding over/under-partitioning; how day→hour partition evolution + sort compaction boosts predicate pruning without exploding costs.
-And most importantly cost-vs-performance.
Who should watch
Data engineers, platform teams, architects, and technical leaders running production Apache Iceberg who want lower cloud bills and stable performance under growing data volumes.
#ApacheIceberg #dataengineering #Lakehouse #spark #Trino #flink #duckdb #clickhouse
OLake website - https://olake.io
OLake GitHub - https://github.com/datazip-inc/olake
Join OLake Slack - https://olake.io/slack
Find us on LinkedIn - https://www.linkedin.com/company/datazipio
➡ MongoDB to Apache Iceberg getting started - https://olake.io/docs/getting-started/mongodb
➡ MySQL to Apache Iceberg getting started -https://olake.io/docs/getting-started/mysql
➡ Postgres to Apache Iceberg getting started -https://olake.io/docs/getting-started/postgres
Видео How to Maintain Apache Iceberg Tables — Monthly Webinar by OLake with Amit Gilad, CTO- Lakeops канала OLake
Комментарии отсутствуют
Информация о видео
26 сентября 2025 г. 16:29:22
01:00:38
Другие видео канала