- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
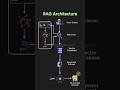
Stop Retraining Your LLM: The Power of Retrieval-Augmented Generation Explained
Want to give your LLM access to private, real-time data without the massive cost of retraining or fine-tuning?
In this video, we break down Retrieval-Augmented Generation (RAG)—the gold standard architecture for GenAI. Learn how to build a pipeline that chunks data, uses vector embeddings, and leverages a Vector Database to provide your AI with the exact context it needs to deliver accurate, up-to-date answers.
What we cover:
Why fine-tuning isn't always the answer.
The role of Vector Databases in AI.
How the retrieval process provides real-time knowledge to LLMs.
If you found this 30-second breakdown helpful, make sure to like and subscribe for more system design insights!
#SystemDesign #GenerativeAI #LLM #RAG #MachineLearning #VectorDatabase #AIArchitecture #SoftwareEngineering #TechIn30Seconds
Видео Stop Retraining Your LLM: The Power of Retrieval-Augmented Generation Explained канала SystemDesignIn30seconds
In this video, we break down Retrieval-Augmented Generation (RAG)—the gold standard architecture for GenAI. Learn how to build a pipeline that chunks data, uses vector embeddings, and leverages a Vector Database to provide your AI with the exact context it needs to deliver accurate, up-to-date answers.
What we cover:
Why fine-tuning isn't always the answer.
The role of Vector Databases in AI.
How the retrieval process provides real-time knowledge to LLMs.
If you found this 30-second breakdown helpful, make sure to like and subscribe for more system design insights!
#SystemDesign #GenerativeAI #LLM #RAG #MachineLearning #VectorDatabase #AIArchitecture #SoftwareEngineering #TechIn30Seconds
Видео Stop Retraining Your LLM: The Power of Retrieval-Augmented Generation Explained канала SystemDesignIn30seconds
Комментарии отсутствуют
Информация о видео
27 марта 2026 г. 17:55:31
00:00:26
Другие видео канала