- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
Bot Thoughts Podcast — LLM-as-a-Judge in Production: Why Your Eval Pipeline Is Lying to You
Level: Advanced
🎙️ Bot Thoughts Podcast — Episode P039
Why your LLM-as-a-judge eval pipeline is silently lying to you, and the structural fix that catches it before users do.
A team I know shipped a prompt change their LLM judge said was 31% better. Pairwise win rate, 78%. Graphs all green. By Thursday, customer CSAT had dropped 11 points. The judge wasn't broken. It was perfectly calibrated to the wrong thing.
In this episode Alex and Sam go deep on:
• The five known judge biases (position, length, self-preference, sycophancy, refusal) and the documented mitigation for each
• Why pairwise judging without position swap is non-negotiable, and the 18% bias we measured on a real customer-support task
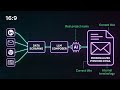
• The three-layer eval stack: programmatic unit eval, calibrated LLM judge ensemble, human-rater calibration
• Why the calibration set's job is to evaluate the judge, not the candidate
• The eval-set bias that survives every other mitigation, and the continuous production-sampling discipline that fixes it
• Why your judge prompt is critical infrastructure that deserves git, code review, and CI gates
Companion blog post (full code, calibration loop architecture, rubric template):
https://amtocsoft.blogspot.com/2026/05/llm-as-judge-in-production-why-your.html
Subscribe to Bot Thoughts on Spotify and Apple Podcasts.
Support the show:
https://buymeacoffee.com/amtocsoft
Show: Bot Thoughts by AmtocSoft
Episode: P039
Length: 16 min
Level: Advanced
Topic: LLM Eval, Production AI
#LLMEval #LLMasaJudge #AIEvaluation #ProductionAI #AIQuality #Podcast
Видео Bot Thoughts Podcast — LLM-as-a-Judge in Production: Why Your Eval Pipeline Is Lying to You канала Toc am
🎙️ Bot Thoughts Podcast — Episode P039
Why your LLM-as-a-judge eval pipeline is silently lying to you, and the structural fix that catches it before users do.
A team I know shipped a prompt change their LLM judge said was 31% better. Pairwise win rate, 78%. Graphs all green. By Thursday, customer CSAT had dropped 11 points. The judge wasn't broken. It was perfectly calibrated to the wrong thing.
In this episode Alex and Sam go deep on:
• The five known judge biases (position, length, self-preference, sycophancy, refusal) and the documented mitigation for each
• Why pairwise judging without position swap is non-negotiable, and the 18% bias we measured on a real customer-support task
• The three-layer eval stack: programmatic unit eval, calibrated LLM judge ensemble, human-rater calibration
• Why the calibration set's job is to evaluate the judge, not the candidate
• The eval-set bias that survives every other mitigation, and the continuous production-sampling discipline that fixes it
• Why your judge prompt is critical infrastructure that deserves git, code review, and CI gates
Companion blog post (full code, calibration loop architecture, rubric template):
https://amtocsoft.blogspot.com/2026/05/llm-as-judge-in-production-why-your.html
Subscribe to Bot Thoughts on Spotify and Apple Podcasts.
Support the show:
https://buymeacoffee.com/amtocsoft
Show: Bot Thoughts by AmtocSoft
Episode: P039
Length: 16 min
Level: Advanced
Topic: LLM Eval, Production AI
#LLMEval #LLMasaJudge #AIEvaluation #ProductionAI #AIQuality #Podcast
Видео Bot Thoughts Podcast — LLM-as-a-Judge in Production: Why Your Eval Pipeline Is Lying to You канала Toc am
Комментарии отсутствуют
Информация о видео
3 мая 2026 г. 14:48:06
00:16:17
Другие видео канала