- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
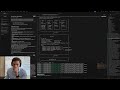
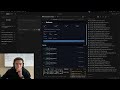
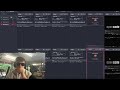
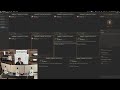
OpenAI buried the SWE-bench Pro results deep inside their GPT-5.5 launch blog.
OpenAI buried the SWE-bench Pro results deep inside their GPT-5.5 launch blog.
The new model dominates Terminal Bench 2.0, scoring an 82.7% compared to the 69.4% from Claude 4 Opus.
But when you are vibe coding, the metrics that actually matter are SWE-bench Pro and SWE-bench Verified. You have to scroll endlessly past the highlight reel just to find how it actually performs on these benchmarks.
Drop a comment with your thoughts on the new benchmarks.
#vibecoding #agenticcoding #aicoding #shipfast #promptengineering #aiagents #buildthefuture
Видео OpenAI buried the SWE-bench Pro results deep inside their GPT-5.5 launch blog. канала BridgeMind
The new model dominates Terminal Bench 2.0, scoring an 82.7% compared to the 69.4% from Claude 4 Opus.
But when you are vibe coding, the metrics that actually matter are SWE-bench Pro and SWE-bench Verified. You have to scroll endlessly past the highlight reel just to find how it actually performs on these benchmarks.
Drop a comment with your thoughts on the new benchmarks.
#vibecoding #agenticcoding #aicoding #shipfast #promptengineering #aiagents #buildthefuture
Видео OpenAI buried the SWE-bench Pro results deep inside their GPT-5.5 launch blog. канала BridgeMind
Комментарии отсутствуют
Информация о видео
6 мая 2026 г. 19:03:27
00:00:43
Другие видео канала