- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
TN - DSAI -108 | Session : 2
In this lecture, we continue our Machine Learning journey with hands-on implementation and deep understanding of how real ML projects are built step by step. The focus is on converting raw data into a clean dataset, splitting it for training/testing, and understanding the first predictive model using Linear Regression.
This session is highly practical and builds the foundation for every machine learning project pipeline.
📌 What You Will Learn in This Class:
We start by revising the previous concepts of data preprocessing and move forward into actual model building.
🔹 1. Data Preparation for Machine Learning
Understanding X (features) and Y (target variable)
Why we drop unnecessary columns (like survival column in Titanic example)
Selecting meaningful features for prediction
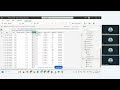
🔹 2. Train-Test Split (Very Important Concept)
Splitting dataset into:
Training Data (80%)
Testing Data (20%)
Using train_test_split from Scikit-Learn
Importance of random_state for reproducibility
Why data consistency matters in ML experiments
🔹 3. Introduction to Model Training
First machine learning model: Linear Regression
What is regression and how it works in real-world predictions
Training the model using .fit() method
🔹 4. Model Prediction & Evaluation
Predicting output using trained model
Comparing predicted values vs actual values
Introduction to Mean Squared Error (MSE)
Why evaluation is necessary in machine learning
🔹 5. Understanding Model Performance
How to check if model is good or bad
Basic idea of accuracy vs error
Introduction to model improvement process
📊 Advanced Concepts Introduced:
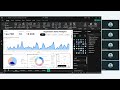
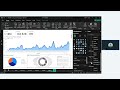
🔹 Correlation Matrix (Heatmap)
Understanding relationship between variables
Positive and negative correlation
Identifying strong and weak feature relationships
🔹 Introduction to Regularization:
Ridge Regression (L2 Regularization)
Lasso Regression (L1 Regularization)
Why penalty is used in machine learning models
How regularization helps prevent overfitting
🧠 Key Concepts Covered:
Machine Learning Pipeline, Data Preprocessing, Feature Selection, Train Test Split, Linear Regression, Model Training, Prediction, Mean Squared Error, Correlation Matrix, Ridge Regression, Lasso Regression
⚙️ Libraries Used:
Pandas
NumPy
Scikit-Learn
Matplotlib / Seaborn
🚀 Why This Lecture is Important:
This session builds the core foundation of machine learning workflow:
Raw Data → Preprocessing → Feature Selection → Train-Test Split → Model Training → Prediction → Evaluation → Improvement
Once you understand this pipeline, you can build any machine learning project.
📌 Hashtags:
#MachineLearning #DataScience #Python #LinearRegression #ScikitLearn #TrainTestSplit #DataPreprocessing #AI #ArtificialIntelligence #MLProject #DataAnalytics #CorrelationMatrix #RidgeRegression #LassoRegression #MSE #SupervisedLearning #Coding #TechEducation #AIForBeginners #DeepLearningBasics
Видео TN - DSAI -108 | Session : 2 канала Palin Analytics
This session is highly practical and builds the foundation for every machine learning project pipeline.
📌 What You Will Learn in This Class:
We start by revising the previous concepts of data preprocessing and move forward into actual model building.
🔹 1. Data Preparation for Machine Learning
Understanding X (features) and Y (target variable)
Why we drop unnecessary columns (like survival column in Titanic example)
Selecting meaningful features for prediction
🔹 2. Train-Test Split (Very Important Concept)
Splitting dataset into:
Training Data (80%)
Testing Data (20%)
Using train_test_split from Scikit-Learn
Importance of random_state for reproducibility
Why data consistency matters in ML experiments
🔹 3. Introduction to Model Training
First machine learning model: Linear Regression
What is regression and how it works in real-world predictions
Training the model using .fit() method
🔹 4. Model Prediction & Evaluation
Predicting output using trained model
Comparing predicted values vs actual values
Introduction to Mean Squared Error (MSE)
Why evaluation is necessary in machine learning
🔹 5. Understanding Model Performance
How to check if model is good or bad
Basic idea of accuracy vs error
Introduction to model improvement process
📊 Advanced Concepts Introduced:
🔹 Correlation Matrix (Heatmap)
Understanding relationship between variables
Positive and negative correlation
Identifying strong and weak feature relationships
🔹 Introduction to Regularization:
Ridge Regression (L2 Regularization)
Lasso Regression (L1 Regularization)
Why penalty is used in machine learning models
How regularization helps prevent overfitting
🧠 Key Concepts Covered:
Machine Learning Pipeline, Data Preprocessing, Feature Selection, Train Test Split, Linear Regression, Model Training, Prediction, Mean Squared Error, Correlation Matrix, Ridge Regression, Lasso Regression
⚙️ Libraries Used:
Pandas
NumPy
Scikit-Learn
Matplotlib / Seaborn
🚀 Why This Lecture is Important:
This session builds the core foundation of machine learning workflow:
Raw Data → Preprocessing → Feature Selection → Train-Test Split → Model Training → Prediction → Evaluation → Improvement
Once you understand this pipeline, you can build any machine learning project.
📌 Hashtags:
#MachineLearning #DataScience #Python #LinearRegression #ScikitLearn #TrainTestSplit #DataPreprocessing #AI #ArtificialIntelligence #MLProject #DataAnalytics #CorrelationMatrix #RidgeRegression #LassoRegression #MSE #SupervisedLearning #Coding #TechEducation #AIForBeginners #DeepLearningBasics
Видео TN - DSAI -108 | Session : 2 канала Palin Analytics
Комментарии отсутствуют
Информация о видео
12 мая 2026 г. 18:01:21
01:07:32
Другие видео канала