- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
Apply parallélisé pour DataFrame Pandas Python
Solutions de parallélisation de la fonction « apply » de Pandas qui applique séquentiellement une fonction sur des colonnes d’un DataFrame Pandas. Le cadre spécifique où les calculs sont indépendants d’une colonne à l’autre. La décomposition des traitements et la consolidation des résultats sont très simplifiées. La parallélisation est alors d’une simplicité désarmante (traduit étrangement en « embarrasingly parallel problem » en anglais). Etude des fonctions « apply » parallélisées des librairies « Modin » (avec le moteur "dask") et « Pandarallel ». Comparaison des temps de traitement sur une base benchmark. Les gains en durée d’exécution sont substantiels avec une modification négligeable du code.
Pandas Apply : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.apply.html
Modin : https://pypi.org/project/modin/
Pandarallel : https://pypi.org/project/pandarallel/
Vidéo - Solution pour R : https://www.youtube.com/watch?v=Vwx3wZ3gl_M
Notebook : https://tutoriels-data-science.blogspot.com/p/tutoriels-en-francais.html
00:00 Parallélisation facile du traitement des data frame Pandas
03:28 Démarrage du notebook
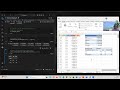
04:37 Génération du data frame à traiter
05:06 Fonction applicable à chaque colonne du data frame
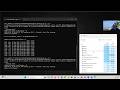
07:15 Traitement séquentiel avec une boucle
08:38 Traitement séquentiel avec apply de Pandas
10:57 Apply rapide de Pandas (basé sur Numba)
14:36 Parallélisation avec "modin" (moteur dask)
17:07 Réécriture (très simple) de la fonction de traitement
21:23 Parallélisation avec "pandarallel"
22:45 Traitement avec "parallel_apply"
24:05 Bilan - Comparaison des temps de calcul
Видео Apply parallélisé pour DataFrame Pandas Python канала MASTER 2 SISE DATA SCIENCE
Pandas Apply : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.apply.html
Modin : https://pypi.org/project/modin/
Pandarallel : https://pypi.org/project/pandarallel/
Vidéo - Solution pour R : https://www.youtube.com/watch?v=Vwx3wZ3gl_M
Notebook : https://tutoriels-data-science.blogspot.com/p/tutoriels-en-francais.html
00:00 Parallélisation facile du traitement des data frame Pandas
03:28 Démarrage du notebook
04:37 Génération du data frame à traiter
05:06 Fonction applicable à chaque colonne du data frame
07:15 Traitement séquentiel avec une boucle
08:38 Traitement séquentiel avec apply de Pandas
10:57 Apply rapide de Pandas (basé sur Numba)
14:36 Parallélisation avec "modin" (moteur dask)
17:07 Réécriture (très simple) de la fonction de traitement
21:23 Parallélisation avec "pandarallel"
22:45 Traitement avec "parallel_apply"
24:05 Bilan - Comparaison des temps de calcul
Видео Apply parallélisé pour DataFrame Pandas Python канала MASTER 2 SISE DATA SCIENCE
Комментарии отсутствуют
Информация о видео
30 января 2025 г. 22:28:48
00:26:46
Другие видео канала