- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
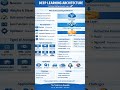
🚀 LLM SERIES (9/10)🔍 Retrieval Augmented Generation (RAG)
🚀 LLM SERIES (9/10)
🔍 Retrieval Augmented Generation (RAG)
LLMs are powerful.
But they don’t have real-time knowledge.
That’s why modern AI systems use RAG Architecture.
⚙️ How RAG Works
Flow:
User Query
→ Embed
→ Vector DB
→ Retrieve
→ Inject Context
→ Generate Answer
Instead of guessing, the model first retrieves relevant information and then generates a grounded response.
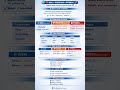
🔥 Why RAG is Needed?
✅ Reduces hallucination
✅ Adds real-time knowledge
✅ Improves factual accuracy
✅ Works with private / enterprise data
No retraining required. Just smarter retrieval.
🏢 Used In:
• Enterprise AI systems
• Internal knowledge assistants
• Customer support automation
• Legal & financial AI tools
💡 Key Insight:
LLM alone = Pattern predictor
LLM + RAG = Grounded AI system
This is how production-grade AI is built.
Series 10 (Finale) dropping next 🔥
Follow for complete LLM mastery.
The ThinkLab by Saurabh
#LLM #RAG #AIArchitecture #GenAI #EnterpriseAI #ArtificialIntelligence
Видео 🚀 LLM SERIES (9/10)🔍 Retrieval Augmented Generation (RAG) канала The ThinkLab by Saurabh
🔍 Retrieval Augmented Generation (RAG)
LLMs are powerful.
But they don’t have real-time knowledge.
That’s why modern AI systems use RAG Architecture.
⚙️ How RAG Works
Flow:
User Query
→ Embed
→ Vector DB
→ Retrieve
→ Inject Context
→ Generate Answer
Instead of guessing, the model first retrieves relevant information and then generates a grounded response.
🔥 Why RAG is Needed?
✅ Reduces hallucination
✅ Adds real-time knowledge
✅ Improves factual accuracy
✅ Works with private / enterprise data
No retraining required. Just smarter retrieval.
🏢 Used In:
• Enterprise AI systems
• Internal knowledge assistants
• Customer support automation
• Legal & financial AI tools
💡 Key Insight:
LLM alone = Pattern predictor
LLM + RAG = Grounded AI system
This is how production-grade AI is built.
Series 10 (Finale) dropping next 🔥
Follow for complete LLM mastery.
The ThinkLab by Saurabh
#LLM #RAG #AIArchitecture #GenAI #EnterpriseAI #ArtificialIntelligence
Видео 🚀 LLM SERIES (9/10)🔍 Retrieval Augmented Generation (RAG) канала The ThinkLab by Saurabh
Комментарии отсутствуют
Информация о видео
4 марта 2026 г. 18:34:41
00:00:05
Другие видео канала