⚡ SQL One-Liner: Fast Approximate Distinct Counts with APPROX_COUNT_DISTINCT()
When you need a fast, scalable way to count unique users, sessions, or items in a high-volume table, exact COUNT(DISTINCT…) can become a bottleneck. Modern analytics engines like BigQuery, Snowflake, Redshift, and Presto offer the APPROX_COUNT_DISTINCT() function (or equivalent APPROX_DISTINCT() / HLL_COUNT.INIT()) to estimate cardinality with minimal resource usage. This one-liner replaces a costly grouping or hash-based deduplication with a constant-space probabilistic algorithm—ideal for real-time dashboards and big-data pipelines.
Queries:
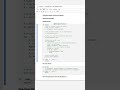
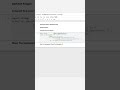
✅ Long Way (Exact Count):
SELECT COUNT(DISTINCT user_id) AS unique_users
FROM events;
Explanation:
This computes the exact number of distinct user_id values in the events table. On very large tables, COUNT(DISTINCT) can be slow and memory-intensive, because the engine must track every unique value.
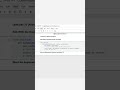
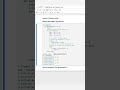
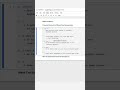
✅ Shortcut One-Liner (Approximate Count for Performance):
SELECT APPROX_COUNT_DISTINCT(user_id) AS unique_users
FROM events;
Explanation:
APPROX_COUNT_DISTINCT() uses a HyperLogLog-style sketch to estimate the number of distinct values in O(1) memory and time per row.
It delivers results that are 99% accurate with a tiny error margin—perfect for dashboards, monitoring, and exploratory queries on massive datasets.
Видео ⚡ SQL One-Liner: Fast Approximate Distinct Counts with APPROX_COUNT_DISTINCT() канала CodeVisium
Queries:
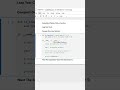
✅ Long Way (Exact Count):
SELECT COUNT(DISTINCT user_id) AS unique_users
FROM events;
Explanation:
This computes the exact number of distinct user_id values in the events table. On very large tables, COUNT(DISTINCT) can be slow and memory-intensive, because the engine must track every unique value.
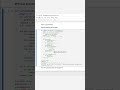
✅ Shortcut One-Liner (Approximate Count for Performance):
SELECT APPROX_COUNT_DISTINCT(user_id) AS unique_users
FROM events;
Explanation:
APPROX_COUNT_DISTINCT() uses a HyperLogLog-style sketch to estimate the number of distinct values in O(1) memory and time per row.
It delivers results that are 99% accurate with a tiny error margin—perfect for dashboards, monitoring, and exploratory queries on massive datasets.
Видео ⚡ SQL One-Liner: Fast Approximate Distinct Counts with APPROX_COUNT_DISTINCT() канала CodeVisium
Комментарии отсутствуют
Информация о видео
22 мая 2025 г. 0:35:37
00:00:10
Другие видео канала