- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
Is LLM Fine-Tuning DEAD? How to Get Pro-Level Performance for Only $18
HOW TO BEAT $10,000 AI TRAINING FOR ONLY $18: TRAINING-FREE GRPO EXPLAINED
Is fine-tuning Large Language Models (LLMs) becoming a thing of the past? In today's video, we are diving into a game-changing research paper from the Tencent Youtu Lab titled Training-Free Group Relative Policy Optimization.
THE PROBLEM WITH TRADITIONAL AI TRAINING
Currently, adapting LLM agents to specialized domains is a nightmare. It requires Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) which are incredibly expensive. For example, training a 32B model can cost around $10,000 and require thousands of high-quality data samples. These fine-tuned models often struggle with generalization, meaning they get good at one thing but lose their overall intelligence.
THE SOLUTION: TRAINING-FREE GRPO
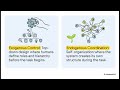
Tencent's researchers have proposed a way to get the benefits of Reinforcement Learning without ever updating the model's actual parameters. This method keeps the model frozen and instead builds an external experience library. This library acts as a token prior that guides the model's behavior during API calls.
HOW IT WORKS: SEMANTIC ADVANTAGE
Traditional GRPO uses mathematical numerical advantages to update model weights. Training-Free GRPO replaces this with a semantic advantage.
1. The model generates multiple answers (rollouts) for a single query.
2. The system compares these answers to see which succeeded and which failed.
3. It then asks the LLM to summarize and distill natural language "experiences" from these comparisons.
4. These experiences are added to a library that the model reads before answering future questions.
THE SHOCKING RESULTS
The researchers tested this on the DeepSeek-V3.1-Terminus model and the results were massive.
- COST: Reduced from $10,000 to approximately $18.
- DATA: Achieved superior results with only 100 training samples instead of thousands.
- MATH PERFORMANCE: On the AIME 2025 benchmark, the model's score jumped from 67.9% to 73.3%.
- WEB SEARCHING: The method significantly improved success rates on the WebWalkerQA benchmark by teaching the agent to prioritize official sources and avoid redundant steps.
This approach proves that guiding a powerful frozen model through context is often more effective and efficient than fine-tuning smaller models.
OFFICIAL LINKS AND RESOURCES
Official Project Code:
https://github.com/TencentCloudADP/youtu-agent/tree/training_free_GRPO
Contact for Researchers:
tristanli@tencent.com
DeepSeek AI Pricing Information:
https://api-docs.deepseek.com/quick_start/pricing
DeepSeek-V3 Technical Report:
https://arxiv.org/abs/2412.19437
AIME Problems and Solutions Wiki:
https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions
Chain-of-Agents Paper:
https://arxiv.org/abs/2508.13167
WebWalker Benchmarking:
https://arxiv.org/abs/2501.07572
Qwen Technical Reports:
https://arxiv.org/abs/2412.15115
https://qwenlm.github.io/blog/qwq-32b/
CREDITS
This research was conducted by the Youtu-Agent Team at Tencent Youtu Lab, including lead authors Yuzheng Cai, Siqi Cai, Yuchen Shi, and Zihan Xu.
#AIAgents #LLM #MachineLearning #AIResearch #PekingUniversity #AgentSkills #ai #artificialintelligence #singularity #agenticai #deepseek #techevolution #futureofwork #softwareengineering #llm #codingagents #tdd #machinelearning #opensource #swebench #qwen #google #stitch #openai #anthropic #claude #openclaw #TimesFM #TimesFM2.5
#coral #langchain #deepseek #v4
Видео Is LLM Fine-Tuning DEAD? How to Get Pro-Level Performance for Only $18 канала The Hidden Layer: Decoding Artificial Intelligence
Is fine-tuning Large Language Models (LLMs) becoming a thing of the past? In today's video, we are diving into a game-changing research paper from the Tencent Youtu Lab titled Training-Free Group Relative Policy Optimization.
THE PROBLEM WITH TRADITIONAL AI TRAINING
Currently, adapting LLM agents to specialized domains is a nightmare. It requires Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) which are incredibly expensive. For example, training a 32B model can cost around $10,000 and require thousands of high-quality data samples. These fine-tuned models often struggle with generalization, meaning they get good at one thing but lose their overall intelligence.
THE SOLUTION: TRAINING-FREE GRPO
Tencent's researchers have proposed a way to get the benefits of Reinforcement Learning without ever updating the model's actual parameters. This method keeps the model frozen and instead builds an external experience library. This library acts as a token prior that guides the model's behavior during API calls.
HOW IT WORKS: SEMANTIC ADVANTAGE
Traditional GRPO uses mathematical numerical advantages to update model weights. Training-Free GRPO replaces this with a semantic advantage.
1. The model generates multiple answers (rollouts) for a single query.
2. The system compares these answers to see which succeeded and which failed.
3. It then asks the LLM to summarize and distill natural language "experiences" from these comparisons.
4. These experiences are added to a library that the model reads before answering future questions.
THE SHOCKING RESULTS
The researchers tested this on the DeepSeek-V3.1-Terminus model and the results were massive.
- COST: Reduced from $10,000 to approximately $18.
- DATA: Achieved superior results with only 100 training samples instead of thousands.
- MATH PERFORMANCE: On the AIME 2025 benchmark, the model's score jumped from 67.9% to 73.3%.
- WEB SEARCHING: The method significantly improved success rates on the WebWalkerQA benchmark by teaching the agent to prioritize official sources and avoid redundant steps.
This approach proves that guiding a powerful frozen model through context is often more effective and efficient than fine-tuning smaller models.
OFFICIAL LINKS AND RESOURCES
Official Project Code:
https://github.com/TencentCloudADP/youtu-agent/tree/training_free_GRPO
Contact for Researchers:
tristanli@tencent.com
DeepSeek AI Pricing Information:
https://api-docs.deepseek.com/quick_start/pricing
DeepSeek-V3 Technical Report:
https://arxiv.org/abs/2412.19437
AIME Problems and Solutions Wiki:
https://artofproblemsolving.com/wiki/index.php/AIME_Problems_and_Solutions
Chain-of-Agents Paper:
https://arxiv.org/abs/2508.13167
WebWalker Benchmarking:
https://arxiv.org/abs/2501.07572
Qwen Technical Reports:
https://arxiv.org/abs/2412.15115
https://qwenlm.github.io/blog/qwq-32b/
CREDITS
This research was conducted by the Youtu-Agent Team at Tencent Youtu Lab, including lead authors Yuzheng Cai, Siqi Cai, Yuchen Shi, and Zihan Xu.
#AIAgents #LLM #MachineLearning #AIResearch #PekingUniversity #AgentSkills #ai #artificialintelligence #singularity #agenticai #deepseek #techevolution #futureofwork #softwareengineering #llm #codingagents #tdd #machinelearning #opensource #swebench #qwen #google #stitch #openai #anthropic #claude #openclaw #TimesFM #TimesFM2.5
#coral #langchain #deepseek #v4
Видео Is LLM Fine-Tuning DEAD? How to Get Pro-Level Performance for Only $18 канала The Hidden Layer: Decoding Artificial Intelligence
Комментарии отсутствуют
Информация о видео
8 мая 2026 г. 19:01:18
00:07:30
Другие видео канала