- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
How NVIDIA Built a $100M AI Factory in 4 Layers #NVIDIA #AIInfrastructure #GPU
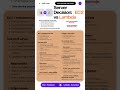
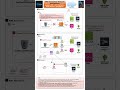
This video details the NVIDIA AI Factory Cloud Provider Platform, highlighting its hardware, networking, and software layers. It illustrates the Kubernetes orchestration, tenant/consumer layer with GPU quotas and namespace isolation, and the monitoring and observability stack using Prometheus and Grafana. The NVIDIA AI Factory leverages advanced GPU technology within its data center infrastructure to power complex AI workloads.
NVIDIA has invested over $4 billion in AI Factory infrastructure — not chatbots, not apps, but the actual GPU-powered data centers underneath all of it.
This image breaks down the complete 4-layer architecture inside an NVIDIA AI Factory:
⏱️ WHAT'S COVERED:
Full Architecture Overview
🔷 Layer 1: Hardware
— DGX SuperPOD with GB300 racks (liquid-cooled)
— 72 Blackwell Ultra GPUs per rack
— NVLink 5 at 1.8 TB/s GPU-to-GPU bandwidth
— Quantum-X800 InfiniBand for RDMA
— 130 TB/s aggregate across 72-GPU domains
🔷 Layer 2: Kubernetes Orchestration
— GPU Operator (drivers, device plugin, DCGM, CDI)
— Run:ai KAI Scheduler (fairshare, gang scheduling, preemption)
— MIG Manager: 1 physical GPU → up to 7 isolated instances
— Network Operator for GPUDirect RDMA + InfiniBand
— Runs on Amazon EKS, vanilla Kubernetes, or OpenShift
🔷 Layer 3: Platform Software
— Base Command Manager (cluster provisioning)
— Mission Control (AI factory operations & automation)
— NVIDIA AI Enterprise (NIM, NeMo, Triton, RAPIDS, TensorRT)
— CUDA, cuDNN, NCCL underneath
🔷 Layer 4: Multi-Tenant Operations
— Namespace isolation per customer/team
— GPU quotas per tenant (e.g., 256 H100s for Tenant A)
— MIG slices or full GPUs per tenant
— DCGM Exporter → Prometheus → Grafana for monitoring
— Per-tenant usage tracking for chargeback billing
📊 Real-World Deployments:
— CoreWeave: $11.5B raised, building GPU cloud with this architecture
— Equinix: AI Factory access across 45+ global markets
— NTT DATA: Deployed for healthcare AI (cancer research) in March 2026
— Nebius: $2B NVIDIA investment for 5+ GW AI factory capacity
🔑 KEY TECHNOLOGIES:
NVIDIA DGX SuperPOD, Blackwell Ultra B300, GB300, NVLink 5, Quantum-X800 InfiniBand, Spectrum-X Ethernet, GPU Operator, Run:ai KAI Scheduler, MIG (Multi-Instance GPU), Base Command Manager, Mission Control, NVIDIA AI Enterprise, NIM Microservices, NeMo Framework, Triton Inference Server, RAPIDS, TensorRT, DCGM Exporter, Kubernetes, Amazon EKS
👉 Follow for more AI infrastructure content.
👉 Like & Subscribe if this was useful.
═══════════════════════════════════
#NVIDIA #AIFactory #Kubernetes #GPU #CloudComputing #AIInfrastructure #DGX #Blackwell #MLOps #DataCenter #tech #cloudcomputing #AIInfrastructure #MLInfrastructure #NVIDIAAIFactory #DGXSuperPOD #NVIDIAAIEnterprise #InfiniBand #Triton #Nemo #RAPIDS #TensorRT #CUDA #cuDNN #NCCL #NIM #DCGM #AIMonitoring #Monitoring #Prometheus #Grafana #NVLink #CloudAI #CloudInfrastructure
Видео How NVIDIA Built a $100M AI Factory in 4 Layers #NVIDIA #AIInfrastructure #GPU канала YV Labs by Vidh Yasa
NVIDIA has invested over $4 billion in AI Factory infrastructure — not chatbots, not apps, but the actual GPU-powered data centers underneath all of it.
This image breaks down the complete 4-layer architecture inside an NVIDIA AI Factory:
⏱️ WHAT'S COVERED:
Full Architecture Overview
🔷 Layer 1: Hardware
— DGX SuperPOD with GB300 racks (liquid-cooled)
— 72 Blackwell Ultra GPUs per rack
— NVLink 5 at 1.8 TB/s GPU-to-GPU bandwidth
— Quantum-X800 InfiniBand for RDMA
— 130 TB/s aggregate across 72-GPU domains
🔷 Layer 2: Kubernetes Orchestration
— GPU Operator (drivers, device plugin, DCGM, CDI)
— Run:ai KAI Scheduler (fairshare, gang scheduling, preemption)
— MIG Manager: 1 physical GPU → up to 7 isolated instances
— Network Operator for GPUDirect RDMA + InfiniBand
— Runs on Amazon EKS, vanilla Kubernetes, or OpenShift
🔷 Layer 3: Platform Software
— Base Command Manager (cluster provisioning)
— Mission Control (AI factory operations & automation)
— NVIDIA AI Enterprise (NIM, NeMo, Triton, RAPIDS, TensorRT)
— CUDA, cuDNN, NCCL underneath
🔷 Layer 4: Multi-Tenant Operations
— Namespace isolation per customer/team
— GPU quotas per tenant (e.g., 256 H100s for Tenant A)
— MIG slices or full GPUs per tenant
— DCGM Exporter → Prometheus → Grafana for monitoring
— Per-tenant usage tracking for chargeback billing
📊 Real-World Deployments:
— CoreWeave: $11.5B raised, building GPU cloud with this architecture
— Equinix: AI Factory access across 45+ global markets
— NTT DATA: Deployed for healthcare AI (cancer research) in March 2026
— Nebius: $2B NVIDIA investment for 5+ GW AI factory capacity
🔑 KEY TECHNOLOGIES:
NVIDIA DGX SuperPOD, Blackwell Ultra B300, GB300, NVLink 5, Quantum-X800 InfiniBand, Spectrum-X Ethernet, GPU Operator, Run:ai KAI Scheduler, MIG (Multi-Instance GPU), Base Command Manager, Mission Control, NVIDIA AI Enterprise, NIM Microservices, NeMo Framework, Triton Inference Server, RAPIDS, TensorRT, DCGM Exporter, Kubernetes, Amazon EKS
👉 Follow for more AI infrastructure content.
👉 Like & Subscribe if this was useful.
═══════════════════════════════════
#NVIDIA #AIFactory #Kubernetes #GPU #CloudComputing #AIInfrastructure #DGX #Blackwell #MLOps #DataCenter #tech #cloudcomputing #AIInfrastructure #MLInfrastructure #NVIDIAAIFactory #DGXSuperPOD #NVIDIAAIEnterprise #InfiniBand #Triton #Nemo #RAPIDS #TensorRT #CUDA #cuDNN #NCCL #NIM #DCGM #AIMonitoring #Monitoring #Prometheus #Grafana #NVLink #CloudAI #CloudInfrastructure
Видео How NVIDIA Built a $100M AI Factory in 4 Layers #NVIDIA #AIInfrastructure #GPU канала YV Labs by Vidh Yasa
nvidia ai kubernetes data center gpu openai ai news kubernetes basics ai infrastructure artificial intelligence amd k8s kubernetes crash course ai factory kubernetes tutorial for beginners rtx 5090 jensen huang training sam altman nvda stock best graphics cards learn kubernetes trainium amazon web services rtx 5060 chip rtx 5070 ti kubernetes architecture gpu buying guide amd vs nvidia tpu kubernetes tutorial what is kubernetes nvidia jensen huang
Комментарии отсутствуют
Информация о видео
15 апреля 2026 г. 3:15:03
00:00:05
Другие видео канала