- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
Microsoft Fabric for Beginners | Pipeline + PySpark + Delta Table + Lakehouse
Git Repo:
https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/sales.csv
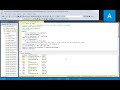
Notebook pyspark transformation code:
from pyspark.sql.functions import *
# Read the new sales data
df = spark.read.format("csv").option("header","true").load("Files/new_data/*.csv")
## Add month and year columns
df = df.withColumn("Year", year(col("OrderDate"))).withColumn("Month", month(col("OrderDate")))
# Derive FirstName and LastName columns
df = df.withColumn("FirstName", split(col("CustomerName"), " ").getItem(0)).withColumn("LastName", split(col("CustomerName"), " ").getItem(1))
# Filter and reorder columns
df = df["SalesOrderNumber", "SalesOrderLineNumber", "OrderDate", "Year", "Month", "FirstName", "LastName", "EmailAddress", "Item", "Quantity", "UnitPrice", "TaxAmount"]
# Load the data into a table
df.write.format("delta").mode("append").saveAsTable(table_name)
Видео Microsoft Fabric for Beginners | Pipeline + PySpark + Delta Table + Lakehouse канала Data Analytics
https://raw.githubusercontent.com/MicrosoftLearning/dp-data/main/sales.csv
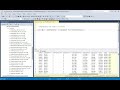
Notebook pyspark transformation code:
from pyspark.sql.functions import *
# Read the new sales data
df = spark.read.format("csv").option("header","true").load("Files/new_data/*.csv")
## Add month and year columns
df = df.withColumn("Year", year(col("OrderDate"))).withColumn("Month", month(col("OrderDate")))
# Derive FirstName and LastName columns
df = df.withColumn("FirstName", split(col("CustomerName"), " ").getItem(0)).withColumn("LastName", split(col("CustomerName"), " ").getItem(1))
# Filter and reorder columns
df = df["SalesOrderNumber", "SalesOrderLineNumber", "OrderDate", "Year", "Month", "FirstName", "LastName", "EmailAddress", "Item", "Quantity", "UnitPrice", "TaxAmount"]
# Load the data into a table
df.write.format("delta").mode("append").saveAsTable(table_name)
Видео Microsoft Fabric for Beginners | Pipeline + PySpark + Delta Table + Lakehouse канала Data Analytics
Комментарии отсутствуют
Информация о видео
7 марта 2026 г. 4:00:16
00:23:47
Другие видео канала