- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
How to Evaluate RAG Systems with Python (Pandas & Golden Datasets)
Building a retrieval-augmented generation (RAG) pipeline is one thing; proving that it actually works in a production environment is another entirely.
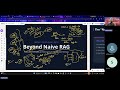
In this capstone session, we design and evaluate a complete RAG architecture for a real-world business (a mobile accessories site). We pull down their public policies, chunk the data, embed it into a local ChromaDB vector store, and test the precision of our semantic search.
We break down the critical difference between blind character-limit chunking and "Semantic Chunking," exploring why preserving line breaks and paragraph structures prevents catastrophic data loss during embedding.
Finally, we write a Python script using Pandas to test our retrieval engine against a "Golden Dataset." We configure a local Llama 3.2 model as a strict judge (Temperature = 0) to compare the retrieved context against our verified ground truths, logging the faithfulness scores to identify exactly where our pipeline hallucinates or fails.
Key Takeaways:
Semantic Chunking: Blindly slicing a document by token limits destroys context. A smart RAG pipeline chunks text semantically—breaking at natural paragraphs, headers, or line endings to ensure every vector maintains a complete logical thought.
Overlap Strategy: When chunking text, you must implement an overlap (e.g., 100 characters). This ensures that a concept split across two chunks still retains enough context to be correctly retrieved during a vector search.
Zero-Temperature Auditing: When using an LLM to judge your RAG pipeline's accuracy, you do not want it to be creative. Setting the temperature to 0 forces the model to act deterministically, returning strict numerical ratings instead of rambling justifications.
Видео How to Evaluate RAG Systems with Python (Pandas & Golden Datasets) канала Logically ILLogical
In this capstone session, we design and evaluate a complete RAG architecture for a real-world business (a mobile accessories site). We pull down their public policies, chunk the data, embed it into a local ChromaDB vector store, and test the precision of our semantic search.
We break down the critical difference between blind character-limit chunking and "Semantic Chunking," exploring why preserving line breaks and paragraph structures prevents catastrophic data loss during embedding.
Finally, we write a Python script using Pandas to test our retrieval engine against a "Golden Dataset." We configure a local Llama 3.2 model as a strict judge (Temperature = 0) to compare the retrieved context against our verified ground truths, logging the faithfulness scores to identify exactly where our pipeline hallucinates or fails.
Key Takeaways:
Semantic Chunking: Blindly slicing a document by token limits destroys context. A smart RAG pipeline chunks text semantically—breaking at natural paragraphs, headers, or line endings to ensure every vector maintains a complete logical thought.
Overlap Strategy: When chunking text, you must implement an overlap (e.g., 100 characters). This ensures that a concept split across two chunks still retains enough context to be correctly retrieved during a vector search.
Zero-Temperature Auditing: When using an LLM to judge your RAG pipeline's accuracy, you do not want it to be creative. Setting the temperature to 0 forces the model to act deterministically, returning strict numerical ratings instead of rambling justifications.
Видео How to Evaluate RAG Systems with Python (Pandas & Golden Datasets) канала Logically ILLogical
Комментарии отсутствуют
Информация о видео
29 мая 2026 г. 0:04:19
00:34:11
Другие видео канала