- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
What are Schema Inference, Write and Read Schemas?
Lesser known facts about schemas:
What is schema inference?
What are write and read schemas?
When to use both?
Try Estuary for free: https://www.estuary.dev/
Join our Slack channel with a community of developers:
https://estuary-dev.slack.com/
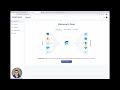
Flow documents and collections always have an associated schema that defines the structure, representation, and constraints of your documents. Collections must have one schema, but may have two distinct schemas: one for when documents are added to the collection, and one for when documents are read from that collection.
Schemas are a powerful tool for data quality. Flow verifies every document against its schema whenever it's read or written, which provides a strong guarantee that your collections hold only "clean" data, and that bugs and invalid documents are caught before they can impact downstream data products.
In most cases, Flow generates a functioning schema on your behalf during the discovery phase of capture. In advanced use cases, however, customizing your schema becomes more important.
Flow performs static inference of the collection schema to verify the existence and types of all keyed document locations, and will report an error if the location could not exist, or could exist with the wrong type.
#schema #estuaryflow #data #dataops #dataengineering #datapipeline
Видео What are Schema Inference, Write and Read Schemas? канала Estuary
What is schema inference?
What are write and read schemas?
When to use both?
Try Estuary for free: https://www.estuary.dev/
Join our Slack channel with a community of developers:
https://estuary-dev.slack.com/
Flow documents and collections always have an associated schema that defines the structure, representation, and constraints of your documents. Collections must have one schema, but may have two distinct schemas: one for when documents are added to the collection, and one for when documents are read from that collection.
Schemas are a powerful tool for data quality. Flow verifies every document against its schema whenever it's read or written, which provides a strong guarantee that your collections hold only "clean" data, and that bugs and invalid documents are caught before they can impact downstream data products.
In most cases, Flow generates a functioning schema on your behalf during the discovery phase of capture. In advanced use cases, however, customizing your schema becomes more important.
Flow performs static inference of the collection schema to verify the existence and types of all keyed document locations, and will report an error if the location could not exist, or could exist with the wrong type.
#schema #estuaryflow #data #dataops #dataengineering #datapipeline
Видео What are Schema Inference, Write and Read Schemas? канала Estuary
Комментарии отсутствуют
Информация о видео
20 марта 2023 г. 5:39:30
00:04:19
Другие видео канала