[Transformer] Attention Is All You Need | AISC Foundational
22 October 2018
For slides and more information, visit https://aisc.ai.science/events/2018-10-22
Paper: https://arxiv.org/abs/1706.03762
Speaker: Joseph Palermo (Dessa)
Host: Insight
Date: Oct 22nd, 2018
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
Видео [Transformer] Attention Is All You Need | AISC Foundational канала ML Explained - Aggregate Intellect - AI.SCIENCE
For slides and more information, visit https://aisc.ai.science/events/2018-10-22
Paper: https://arxiv.org/abs/1706.03762
Speaker: Joseph Palermo (Dessa)
Host: Insight
Date: Oct 22nd, 2018
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
Видео [Transformer] Attention Is All You Need | AISC Foundational канала ML Explained - Aggregate Intellect - AI.SCIENCE
Показать
Комментарии отсутствуют
Информация о видео
1 ноября 2018 г. 9:03:12
00:54:13
Другие видео канала
 Code Review: Transformer - Attention Is All You Need | AISC
Code Review: Transformer - Attention Is All You Need | AISC Transformer Neural Networks - EXPLAINED! (Attention is all you need)
Transformer Neural Networks - EXPLAINED! (Attention is all you need) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding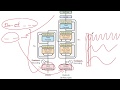 Attention Is All You Need
Attention Is All You Need![[ELMo] Deep Contextualized Word Representations | AISC](https://i.ytimg.com/vi/9JfGxKkmBc0/default.jpg) [ELMo] Deep Contextualized Word Representations | AISC
[ELMo] Deep Contextualized Word Representations | AISC Ivan Bilan: Understanding and Applying Self-Attention for NLP | PyData Berlin 2018
Ivan Bilan: Understanding and Applying Self-Attention for NLP | PyData Berlin 2018
 Attention is all you need; Attentional Neural Network Models | Łukasz Kaiser | Masterclass
Attention is all you need; Attentional Neural Network Models | Łukasz Kaiser | Masterclass Learning a language? Speak it like you’re playing a video game | Marianna Pascal | TEDxPenangRoad
Learning a language? Speak it like you’re playing a video game | Marianna Pascal | TEDxPenangRoad Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 8 – Translation, Seq2Seq, Attention
Stanford CS224N: NLP with Deep Learning | Winter 2019 | Lecture 8 – Translation, Seq2Seq, Attention DETR: End-to-End Object Detection with Transformers (Paper Explained)
DETR: End-to-End Object Detection with Transformers (Paper Explained)![[BERT] Pretranied Deep Bidirectional Transformers for Language Understanding (algorithm) | TDLS](https://i.ytimg.com/vi/BhlOGGzC0Q0/default.jpg) [BERT] Pretranied Deep Bidirectional Transformers for Language Understanding (algorithm) | TDLS
[BERT] Pretranied Deep Bidirectional Transformers for Language Understanding (algorithm) | TDLS Elon Musk: The Scientist Behind the CEO (and How He Teaches Himself) Documentary
Elon Musk: The Scientist Behind the CEO (and How He Teaches Himself) Documentary DINO: Emerging Properties in Self-Supervised Vision Transformers (Facebook AI Research Explained)
DINO: Emerging Properties in Self-Supervised Vision Transformers (Facebook AI Research Explained) Intuition Behind Self-Attention Mechanism in Transformer Networks
Intuition Behind Self-Attention Mechanism in Transformer Networks Vision Transformer in PyTorch
Vision Transformer in PyTorch![[딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습)](https://i.ytimg.com/vi/AA621UofTUA/default.jpg) [딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습)
[딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습) Visual Guide to Transformer Neural Networks - (Episode 2) Multi-Head & Self-Attention
Visual Guide to Transformer Neural Networks - (Episode 2) Multi-Head & Self-Attention Pay Attention to the Signs of the Universe | Jack Canfield
Pay Attention to the Signs of the Universe | Jack Canfield Sequence to Sequence Learning with Encoder-Decoder Neural Network Models by Dr. Ananth Sankar
Sequence to Sequence Learning with Encoder-Decoder Neural Network Models by Dr. Ananth Sankar