- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
I Benchmarked 3 LLM Servers… The Result Surprised Me #LLM #AIInfrastructure #vLLM #Ollama
🚀 In this video we benchmark three popular LLM serving engines:
• vLLM
• SGLang
• Ollama
The goal is to test how well they handle **concurrent inference requests** when running the same model on the same GPU.
As more developers deploy local LLM APIs, the serving layer becomes just as important as the model itself.
So the question is:
Which inference engine performs best under load?
⚙️ Benchmark Setup
Model: Qwen/Qwen3.5-0.8B
Hardware: Single GPU
Concurrent Requests: 16 (4 for Ollama)
Test: Identical prompt workload across engines
📊 What we measure
• Total response time
• Throughput
• Concurrency performance
• Stability under load
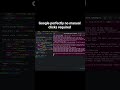
🔬 Results
SGLang delivered the fastest total runtime in this test, while vLLM showed strong throughput performance. Ollama was simpler to run but slower under heavy concurrency.
📂 Project Repository
https://github.com/zkzkGamal/concurrent-llm-serving
Feel free to reproduce the benchmark, test other models, or contribute improvements.
💡 Future Experiments
• Larger models (7B / 13B)
• Multi-GPU setups
• Kubernetes deployments
• Real production workloads
If you're interested in AI infrastructure, LLM serving, or GPU performance tuning — subscribe for more experiments.
#LLM #AIInfrastructure #vLLM #Ollama #MachineLearning #AIEngineering
Видео I Benchmarked 3 LLM Servers… The Result Surprised Me #LLM #AIInfrastructure #vLLM #Ollama канала zkaria gamal
• vLLM
• SGLang
• Ollama
The goal is to test how well they handle **concurrent inference requests** when running the same model on the same GPU.
As more developers deploy local LLM APIs, the serving layer becomes just as important as the model itself.
So the question is:
Which inference engine performs best under load?
⚙️ Benchmark Setup
Model: Qwen/Qwen3.5-0.8B
Hardware: Single GPU
Concurrent Requests: 16 (4 for Ollama)
Test: Identical prompt workload across engines
📊 What we measure
• Total response time
• Throughput
• Concurrency performance
• Stability under load
🔬 Results
SGLang delivered the fastest total runtime in this test, while vLLM showed strong throughput performance. Ollama was simpler to run but slower under heavy concurrency.
📂 Project Repository
https://github.com/zkzkGamal/concurrent-llm-serving
Feel free to reproduce the benchmark, test other models, or contribute improvements.
💡 Future Experiments
• Larger models (7B / 13B)
• Multi-GPU setups
• Kubernetes deployments
• Real production workloads
If you're interested in AI infrastructure, LLM serving, or GPU performance tuning — subscribe for more experiments.
#LLM #AIInfrastructure #vLLM #Ollama #MachineLearning #AIEngineering
Видео I Benchmarked 3 LLM Servers… The Result Surprised Me #LLM #AIInfrastructure #vLLM #Ollama канала zkaria gamal
Комментарии отсутствуют
Информация о видео
16 марта 2026 г. 13:55:38
00:00:10
Другие видео канала