- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
What’s Inside a GGUF File? (Local AI Models Explained)
You’ve downloaded the GGUF files.
You run them with Ollama or llama.cpp.
But what’s actually inside them?
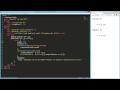
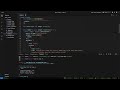
In this video, we break down the GGUF (GGML Unified Format) file structure from top to bottom:
• The 20-byte header
• Metadata key-value pairs
• Tensor info layout
• Memory-mapped loading (mmap)
• Quantization types (F32 → Q2_K)
• K-quants vs legacy quantization
• GGUF naming conventions explained
– Choose the right quantization level
– Optimize RAM usage
– Understand model quality tradeoffs
– Inspect files without loading them
– Debug large model deployments
GGUF is the default format for local LLMs — and now you’ll know exactly how it works.
Chapters:
00:00 Intro
00:30 GG ML Unified Format
01:00 What makes GGUF Different?
01:47 GGUF File Structure
02:46 Read the GGUF Header
03:31 What is Quantization
03:54 GGUF Supported Quantizations
05:45 GGUF File Naming Convention
07:08 Takeaway
• Full GGUF specification - https://github.com/ggml-org/ggml/blob/master/docs/gguf.md
• Python GGUF header inspector script - https://gist.github.com/joemaddalone/f07cf8a575e78ba9a61def91b3ae1bd8
Видео What’s Inside a GGUF File? (Local AI Models Explained) канала Joe Maddalone
You run them with Ollama or llama.cpp.
But what’s actually inside them?
In this video, we break down the GGUF (GGML Unified Format) file structure from top to bottom:
• The 20-byte header
• Metadata key-value pairs
• Tensor info layout
• Memory-mapped loading (mmap)
• Quantization types (F32 → Q2_K)
• K-quants vs legacy quantization
• GGUF naming conventions explained
– Choose the right quantization level
– Optimize RAM usage
– Understand model quality tradeoffs
– Inspect files without loading them
– Debug large model deployments
GGUF is the default format for local LLMs — and now you’ll know exactly how it works.
Chapters:
00:00 Intro
00:30 GG ML Unified Format
01:00 What makes GGUF Different?
01:47 GGUF File Structure
02:46 Read the GGUF Header
03:31 What is Quantization
03:54 GGUF Supported Quantizations
05:45 GGUF File Naming Convention
07:08 Takeaway
• Full GGUF specification - https://github.com/ggml-org/ggml/blob/master/docs/gguf.md
• Python GGUF header inspector script - https://gist.github.com/joemaddalone/f07cf8a575e78ba9a61def91b3ae1bd8
Видео What’s Inside a GGUF File? (Local AI Models Explained) канала Joe Maddalone
Комментарии отсутствуют
Информация о видео
19 мая 2026 г. 18:30:11
00:08:15
Другие видео канала