- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
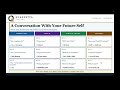
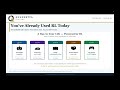
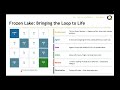
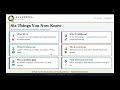
RLF S3L1: When the Map Runs Out — Why Model-Free RL?
This lecture motivates the entire section by showing where Dynamic Programming (DP) breaks down. Students learn why real-world environments — Blackjack, Atari, robotics — make DP impossible to apply, and how Monte Carlo (MC) methods solve this by replacing the "model" with raw experience. We finish with the one-sentence summary of MC: play many episodes, average the returns you see.
Full Course: https://quanzetta.com/courses/reinforcement-learning-foundation/
Видео RLF S3L1: When the Map Runs Out — Why Model-Free RL? канала Quanzetta
Full Course: https://quanzetta.com/courses/reinforcement-learning-foundation/
Видео RLF S3L1: When the Map Runs Out — Why Model-Free RL? канала Quanzetta
Комментарии отсутствуют
Информация о видео
22 мая 2026 г. 0:10:27
00:08:10
Другие видео канала