- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
fully open source RAG stack 2026 #ai #education #job #agenticai #coding
This stack brings together powerful tools to transform raw data into context-rich intelligence. It integrates ingestion pipelines, embeddings, retrieval, and vector databases into one cohesive system.
By layering these components with LLM frameworks and models, it enables scalable, trustworthy, and production-ready AI applications - turning data into meaningful, actionable outputs.
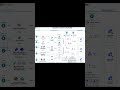
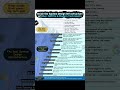
Here’s how the stack comes together:
- Ingest & Data Processing
Kubeflow, Apache Airflow, Apache Nifi, LangChain loaders, Haystack pipelines, and OpenSearch handle data pipelines.
- Retrieval & Ranking
Elasticsearch, Weaviate, FAISS, JinaAI rerankers, and Haystack retrievers fetch and prioritize the most relevant context.
- Embedding Models
HuggingFace Transformers, Sentence Transformers, JinaAI, Cognita, Nomic, and LLMWare turn text into searchable vectors.
- Vector Databases
Milvus, Weaviate, PgVector, Chroma, and Qdrant store embeddings with speed and scale.
- LLM Frameworks
LangChain, Haystack, CrewAI, HuggingFace, and LlamaIndex orchestrate intelligent workflows and tool integration.
- LLMs
Models like LLaMA, Mistral, Phi-2, DeepSeek, Qwen, and Gemma power reasoning and response generation.
- Frontend Frameworks
NextJS, Streamlit, VueJS, and SvelteKit enable user-friendly, interactive AI experiences.
The Open Source RAG Stack is the foundation behind smarter, scalable, and trustworthy AI systems.
What would you add to this stack? Share with me in the comments.
Видео fully open source RAG stack 2026 #ai #education #job #agenticai #coding канала AI DevSecOps Cloud Journey
By layering these components with LLM frameworks and models, it enables scalable, trustworthy, and production-ready AI applications - turning data into meaningful, actionable outputs.
Here’s how the stack comes together:
- Ingest & Data Processing
Kubeflow, Apache Airflow, Apache Nifi, LangChain loaders, Haystack pipelines, and OpenSearch handle data pipelines.
- Retrieval & Ranking
Elasticsearch, Weaviate, FAISS, JinaAI rerankers, and Haystack retrievers fetch and prioritize the most relevant context.
- Embedding Models
HuggingFace Transformers, Sentence Transformers, JinaAI, Cognita, Nomic, and LLMWare turn text into searchable vectors.
- Vector Databases
Milvus, Weaviate, PgVector, Chroma, and Qdrant store embeddings with speed and scale.
- LLM Frameworks
LangChain, Haystack, CrewAI, HuggingFace, and LlamaIndex orchestrate intelligent workflows and tool integration.
- LLMs
Models like LLaMA, Mistral, Phi-2, DeepSeek, Qwen, and Gemma power reasoning and response generation.
- Frontend Frameworks
NextJS, Streamlit, VueJS, and SvelteKit enable user-friendly, interactive AI experiences.
The Open Source RAG Stack is the foundation behind smarter, scalable, and trustworthy AI systems.
What would you add to this stack? Share with me in the comments.
Видео fully open source RAG stack 2026 #ai #education #job #agenticai #coding канала AI DevSecOps Cloud Journey
Комментарии отсутствуют
Информация о видео
14 марта 2026 г. 13:09:17
00:00:31
Другие видео канала