Learning Temporal Co-Attention Models for Unsupervised Video Action Localization
Authors: Guoqiang Gong, Xinghan Wang, Yadong Mu, Qi Tian
Temporal action localization (TAL) in untrimmed videos recently receives tremendous research enthusiasm. To our best knowledge, this is the first attempt in the literature to explore this task under an unsupervised setting, hereafter referred to as action co-localization (ACL), where only the total count of unique actions that appear in the video set is known. To solve ACL, we propose a two-step ``clustering + localization" iterative procedure. The clustering step provides noisy pseudo-labels for the localization step, and the localization step provides temporal co-attention models that in turn improve the clustering performance. Using such two-step procedure, weakly-supervised TAL can be regarded as a direct extension of our ACL model. Technically, our contributions are two-folds: 1) temporal co-attention models, either class-specific or class-agnostic, learned from video-level labels or pseudo-labels in an iterative reinforced fashion. 2) new losses specially designed for ACL, including action-background separation loss and cluster-based triplet loss. Comprehensive evaluations are conducted on 20-action THUMOS14 and 100-action ActivityNet-1.2. On both benchmarks, the proposed model for ACL exhibits strong performances, even surprisingly comparable with state-of-the-art weakly-supervised methods. For example, previous best weakly-supervised model achieves 26.8% under mAP@0.5 on THUMOS14, our new records are 30.1% (weakly-supervised) and 25.0% (unsupervised).
Видео Learning Temporal Co-Attention Models for Unsupervised Video Action Localization канала ComputerVisionFoundation Videos
Temporal action localization (TAL) in untrimmed videos recently receives tremendous research enthusiasm. To our best knowledge, this is the first attempt in the literature to explore this task under an unsupervised setting, hereafter referred to as action co-localization (ACL), where only the total count of unique actions that appear in the video set is known. To solve ACL, we propose a two-step ``clustering + localization" iterative procedure. The clustering step provides noisy pseudo-labels for the localization step, and the localization step provides temporal co-attention models that in turn improve the clustering performance. Using such two-step procedure, weakly-supervised TAL can be regarded as a direct extension of our ACL model. Technically, our contributions are two-folds: 1) temporal co-attention models, either class-specific or class-agnostic, learned from video-level labels or pseudo-labels in an iterative reinforced fashion. 2) new losses specially designed for ACL, including action-background separation loss and cluster-based triplet loss. Comprehensive evaluations are conducted on 20-action THUMOS14 and 100-action ActivityNet-1.2. On both benchmarks, the proposed model for ACL exhibits strong performances, even surprisingly comparable with state-of-the-art weakly-supervised methods. For example, previous best weakly-supervised model achieves 26.8% under mAP@0.5 on THUMOS14, our new records are 30.1% (weakly-supervised) and 25.0% (unsupervised).
Видео Learning Temporal Co-Attention Models for Unsupervised Video Action Localization канала ComputerVisionFoundation Videos
Показать
Комментарии отсутствуют
Информация о видео
14 мая 2021 г. 20:10:38
00:04:57
Другие видео канала
 Attention in Neural Networks
Attention in Neural Networks Video Classification with a CNN-RNN Architecture | Human Activity Recognition
Video Classification with a CNN-RNN Architecture | Human Activity Recognition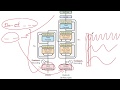 Attention Is All You Need
Attention Is All You Need![CAP5415 Lecture 19 [Action Recognition] - Fall 2020](https://i.ytimg.com/vi/DvbCjcETFV4/default.jpg) CAP5415 Lecture 19 [Action Recognition] - Fall 2020
CAP5415 Lecture 19 [Action Recognition] - Fall 2020 Universal Litmus Patterns: Revealing Backdoor Attacks in CNNs
Universal Litmus Patterns: Revealing Backdoor Attacks in CNNs Efficient Video Recognition - Christoph Feichtenhofer
Efficient Video Recognition - Christoph Feichtenhofer End-to-End Learnable Geometric Vision by Backpropagating PnP Optimization
End-to-End Learnable Geometric Vision by Backpropagating PnP Optimization
 Bring on the learning revolution! | Sir Ken Robinson
Bring on the learning revolution! | Sir Ken Robinson Learning for Video Compression With Hierarchical Quality and Recurrent Enhancement
Learning for Video Compression With Hierarchical Quality and Recurrent Enhancement Temporal Cycle Consistency Learning
Temporal Cycle Consistency Learning Learning from dirty jobs | Mike Rowe
Learning from dirty jobs | Mike Rowe Deep Learning(CS7015): Lec 15.4 Attention over images
Deep Learning(CS7015): Lec 15.4 Attention over images Neha Machine Learning Lead at Wipro | Machine Learning Lead Interview | Applied Ai Course Reviews
Neha Machine Learning Lead at Wipro | Machine Learning Lead Interview | Applied Ai Course Reviews Music Gesture for Visual Sound Separation
Music Gesture for Visual Sound Separation Averaging Essential and Fundamental Matrices in Collinear Camera Settings
Averaging Essential and Fundamental Matrices in Collinear Camera Settings Annotate Videos for Machine Learning Model | Label Videos for Object Detection Model | YOLOv4
Annotate Videos for Machine Learning Model | Label Videos for Object Detection Model | YOLOv4 Clean-Label Backdoor Attacks on Video Recognition Models
Clean-Label Backdoor Attacks on Video Recognition Models High School Quiz Show - The Championship: Advanced Math & Science vs. Lexington (715)
High School Quiz Show - The Championship: Advanced Math & Science vs. Lexington (715) Neural Blind Deconvolution Using Deep Priors
Neural Blind Deconvolution Using Deep Priors