- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
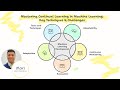
LLM Throughput at Scale: The 4-Layer Answer Candidates Miss | Gen AI Interview Series EP#02
Most engineers stop at continuous batching. Interviewers know the full
stack — vLLM, RadixAttention, Speculative Decoding, Disaggregated
Prefill-Decode. This session covers all four.
In EP#02 of the Gen AI Interview Series, I break down the complete
production answer for LLM inference optimization at scale — the exact
architecture running behind high-throughput serving systems like vLLM
and SGLang.
What you'll learn:
- Why static batching collapses under real bursty traffic — and how
continuous batching fixes GPU idle time at iteration level
- How vLLM's PagedAttention and continuous batching combine for up to
23x throughput gains over naive serving
- How Prefix Caching and RadixAttention (SGLang) eliminate redundant KV
computation across shared prompts
- How Speculative Decoding generates multiple tokens per forward pass —
real 1.5–3x latency gains in production
- Why Disaggregated Prefill-Decode separates compute-heavy and
memory-bound workloads onto dedicated GPU pools
🔗 EP#01 — KV Cache Explained: https://youtu.be/FioRSJU907Y?si=dqxXNFVFaxNC8axc
🔗 Full Gen AI Interview Series Playlist: https://www.youtube.com/playlist?list=PL7lJoDAJY_3yEhgVR-dJ_rJWBMU-h71Vt
#vLLM #LLMInference #AIEngineering #MLOps #GenAIInterviewSeries
Видео LLM Throughput at Scale: The 4-Layer Answer Candidates Miss | Gen AI Interview Series EP#02 канала Shanoj
stack — vLLM, RadixAttention, Speculative Decoding, Disaggregated
Prefill-Decode. This session covers all four.
In EP#02 of the Gen AI Interview Series, I break down the complete
production answer for LLM inference optimization at scale — the exact
architecture running behind high-throughput serving systems like vLLM
and SGLang.
What you'll learn:
- Why static batching collapses under real bursty traffic — and how
continuous batching fixes GPU idle time at iteration level
- How vLLM's PagedAttention and continuous batching combine for up to
23x throughput gains over naive serving
- How Prefix Caching and RadixAttention (SGLang) eliminate redundant KV
computation across shared prompts
- How Speculative Decoding generates multiple tokens per forward pass —
real 1.5–3x latency gains in production
- Why Disaggregated Prefill-Decode separates compute-heavy and
memory-bound workloads onto dedicated GPU pools
🔗 EP#01 — KV Cache Explained: https://youtu.be/FioRSJU907Y?si=dqxXNFVFaxNC8axc
🔗 Full Gen AI Interview Series Playlist: https://www.youtube.com/playlist?list=PL7lJoDAJY_3yEhgVR-dJ_rJWBMU-h71Vt
#vLLM #LLMInference #AIEngineering #MLOps #GenAIInterviewSeries
Видео LLM Throughput at Scale: The 4-Layer Answer Candidates Miss | Gen AI Interview Series EP#02 канала Shanoj
Комментарии отсутствуют
Информация о видео
26 апреля 2026 г. 22:00:02
00:07:22
Другие видео канала