- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
check the description for explanation of commanda
# Data Inspection
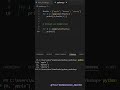
df.columns – shows all column names in the dataframe
df.columns.tolist() – converts column names into a Python list
df.index – shows the row index of the dataframe
df.dtypes – displays the data type of each column
df.describe() – statistical summary for numeric columns
df.describe(include="all") – summary for numeric and categorical columns
df.info() – shows column info, non-null count and data types
df.head() – displays first 5 rows
df.tail() – displays last 5 rows
df.sample() – returns random rows from the dataset
df.nunique() – counts unique values in each column
# Missing Value Analysis
df.isnull().sum() – counts missing values in each column
df.isnull().mean()*100 – percentage of missing values per column
df.isnull().sum().sort_values() – sorts columns by number of missing values
# Value Counts & Distribution
df["col"].value_counts() – counts occurrences of each unique value
df["col"].value_counts(normalize=True) – proportion of each unique value
df["col"].unique() – returns unique values of the column
df["col"].nunique() – total number of unique values
# Removing Duplicates
df["col"].duplicated().sum() – counts duplicate values
df["col"].drop_duplicates() – removes duplicate values
df.drop_duplicates(subset=["col"]) – removes duplicate rows based on a column
# Central Tendency
df["col"].mean() – average value
df["col"].median() – middle value of sorted data
df["col"].mode() – most frequent value
# Measures of Spread
df["col"].std() – standard deviation
df["col"].var() – variance
df["col"].max() – maximum value
df["col"].min() – minimum value
# Shape of Distribution
df["col"].skew() – measures asymmetry of data
df["col"].kurt() – measures heaviness of distribution tails
# Range & Quantiles
max - min – range of values
df["col"].quantile(0.75) – returns 75th percentile
df["col"].quantile([0.25,0.5,0.75]) – returns multiple quantiles
# Correlation Statistics
df.corr(numeric_only=True) – correlation matrix between numeric columns
df.cov(numeric_only=True) – covariance matrix
df["col"].corr(df["col"]) – correlation between two columns
# Visualization
df["col"].hist() – histogram of a column
df["col"].plot() – line plot
df["col"].value_counts().plot(kind="bar") – bar chart of categorical values
df["col"].plot(kind="box") – box plot
df.plot(kind="scatter", x="col", y="col") – scatter plot between two columns
#python
#pandas
#datascience
#machinelearning
#dataanalysis
#pythonprogramming
#learnpython
#pythonforbeginners
#pythoncoding
#eda
#exploratorydataanalysis
#pandaspython
#datasciencetutorial
#coding
#programming
Видео check the description for explanation of commanda канала Your_DataScience_Mentor
df.columns – shows all column names in the dataframe
df.columns.tolist() – converts column names into a Python list
df.index – shows the row index of the dataframe
df.dtypes – displays the data type of each column
df.describe() – statistical summary for numeric columns
df.describe(include="all") – summary for numeric and categorical columns
df.info() – shows column info, non-null count and data types
df.head() – displays first 5 rows
df.tail() – displays last 5 rows
df.sample() – returns random rows from the dataset
df.nunique() – counts unique values in each column
# Missing Value Analysis
df.isnull().sum() – counts missing values in each column
df.isnull().mean()*100 – percentage of missing values per column
df.isnull().sum().sort_values() – sorts columns by number of missing values
# Value Counts & Distribution
df["col"].value_counts() – counts occurrences of each unique value
df["col"].value_counts(normalize=True) – proportion of each unique value
df["col"].unique() – returns unique values of the column
df["col"].nunique() – total number of unique values
# Removing Duplicates
df["col"].duplicated().sum() – counts duplicate values
df["col"].drop_duplicates() – removes duplicate values
df.drop_duplicates(subset=["col"]) – removes duplicate rows based on a column
# Central Tendency
df["col"].mean() – average value
df["col"].median() – middle value of sorted data
df["col"].mode() – most frequent value
# Measures of Spread
df["col"].std() – standard deviation
df["col"].var() – variance
df["col"].max() – maximum value
df["col"].min() – minimum value
# Shape of Distribution
df["col"].skew() – measures asymmetry of data
df["col"].kurt() – measures heaviness of distribution tails
# Range & Quantiles
max - min – range of values
df["col"].quantile(0.75) – returns 75th percentile
df["col"].quantile([0.25,0.5,0.75]) – returns multiple quantiles
# Correlation Statistics
df.corr(numeric_only=True) – correlation matrix between numeric columns
df.cov(numeric_only=True) – covariance matrix
df["col"].corr(df["col"]) – correlation between two columns
# Visualization
df["col"].hist() – histogram of a column
df["col"].plot() – line plot
df["col"].value_counts().plot(kind="bar") – bar chart of categorical values
df["col"].plot(kind="box") – box plot
df.plot(kind="scatter", x="col", y="col") – scatter plot between two columns
#python
#pandas
#datascience
#machinelearning
#dataanalysis
#pythonprogramming
#learnpython
#pythonforbeginners
#pythoncoding
#eda
#exploratorydataanalysis
#pandaspython
#datasciencetutorial
#coding
#programming
Видео check the description for explanation of commanda канала Your_DataScience_Mentor
Комментарии отсутствуют
Информация о видео
5 марта 2026 г. 18:32:04
00:00:15
Другие видео канала