- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
Pytorch LSTM Part 3
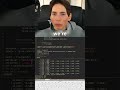
Today we are building an LSTM model in PyTorch, but first we have to finish vectorizing our training data. The model cannot learn from words until we turn each sentence into numbers. We lower case the text, split it into words, and map each word to an index, then we do the same for the tag labels.
A few bugs show up along the way: list comprehensions were hard to read, labels were not shaped right, and the embedding layer would not accept plain lists. We fix that by converting inputs to torch tensors and by padding so every sequence has the same length. We also hit a tricky issue where repeated words overwrote each other in our mapping, so we adjust the loop to handle one word at a time.
By the end, the forward pass runs and we are ready to start training with NLLLoss and SGD.
Видео Pytorch LSTM Part 3 канала Stephen Blum
A few bugs show up along the way: list comprehensions were hard to read, labels were not shaped right, and the embedding layer would not accept plain lists. We fix that by converting inputs to torch tensors and by padding so every sequence has the same length. We also hit a tricky issue where repeated words overwrote each other in our mapping, so we adjust the loop to handle one word at a time.
By the end, the forward pass runs and we are ready to start training with NLLLoss and SGD.
Видео Pytorch LSTM Part 3 канала Stephen Blum
Комментарии отсутствуют
Информация о видео
22 мая 2026 г. 12:00:18
00:24:12
Другие видео канала