- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
🧐👉 Why Google’s New AI Model Runs on Your Phone with Just 1GB #QixNewsAI
📱 Google DeepMind just made on-device AI a reality with Gemma 4 QAT checkpoints!
🔍 What’s new?
- Quantization-Aware Training (QAT) checkpoints for the Gemma 4 family
- A new mobile format that shrinks the E2B model to ~1GB memory
- Text-only version without Per-Layer Embeddings goes under 1GB
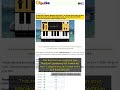
📊 Memory comparison (E2B model):
- BF16 (full precision): 9.6 GB
- Q4_0 QAT (4-bit): 3.2 GB
- Mobile QAT: ~1 GB
⚙️ How the mobile schema works:
- Static activations pre-calculated during training
- Channel-wise quantization for mobile accelerators
- Targeted 2-bit compression on token-generation layers
- Core reasoning layers kept at higher precision
🏆 Format scores (out of 25):
- BF16: 13 — quality baseline, not for phones
- Q4_0 QAT: 21 — best for laptops and consumer GPUs
- Mobile QAT: 21 — best for phones and edge devices
💡 Key takeaways:
- QAT improves quality at a given size, not the size itself
- The mobile format drives the extra memory reduction
- Weights available today on Hugging Face with llama.cpp, Ollama, vLLM, MLX, and LiteRT-LM support
- No independent Gemma 4 QAT benchmark numbers yet, but prior Gemma 3 QAT cut perplexity drop by 54%
🚀 Why it matters:
Developers can now deploy powerful AI locally on phones, Raspberry Pi, and other edge devices without relying on the cloud. This opens up privacy-preserving, low-latency applications for everyone.
#Gemma4QAT #GoogleDeepMind #OnDeviceAI #QuantizationAwareTraining #EdgeComputing #QixNewsAI #Shorts
Видео 🧐👉 Why Google’s New AI Model Runs on Your Phone with Just 1GB #QixNewsAI канала QixNews
🔍 What’s new?
- Quantization-Aware Training (QAT) checkpoints for the Gemma 4 family
- A new mobile format that shrinks the E2B model to ~1GB memory
- Text-only version without Per-Layer Embeddings goes under 1GB
📊 Memory comparison (E2B model):
- BF16 (full precision): 9.6 GB
- Q4_0 QAT (4-bit): 3.2 GB
- Mobile QAT: ~1 GB
⚙️ How the mobile schema works:
- Static activations pre-calculated during training
- Channel-wise quantization for mobile accelerators
- Targeted 2-bit compression on token-generation layers
- Core reasoning layers kept at higher precision
🏆 Format scores (out of 25):
- BF16: 13 — quality baseline, not for phones
- Q4_0 QAT: 21 — best for laptops and consumer GPUs
- Mobile QAT: 21 — best for phones and edge devices
💡 Key takeaways:
- QAT improves quality at a given size, not the size itself
- The mobile format drives the extra memory reduction
- Weights available today on Hugging Face with llama.cpp, Ollama, vLLM, MLX, and LiteRT-LM support
- No independent Gemma 4 QAT benchmark numbers yet, but prior Gemma 3 QAT cut perplexity drop by 54%
🚀 Why it matters:
Developers can now deploy powerful AI locally on phones, Raspberry Pi, and other edge devices without relying on the cloud. This opens up privacy-preserving, low-latency applications for everyone.
#Gemma4QAT #GoogleDeepMind #OnDeviceAI #QuantizationAwareTraining #EdgeComputing #QixNewsAI #Shorts
Видео 🧐👉 Why Google’s New AI Model Runs on Your Phone with Just 1GB #QixNewsAI канала QixNews
Комментарии отсутствуют
Информация о видео
6 июня 2026 г. 19:19:35
00:00:30
Другие видео канала