- Популярные видео
- Авто
- Видео-блоги
- ДТП, аварии
- Для маленьких
- Еда, напитки
- Животные
- Закон и право
- Знаменитости
- Игры
- Искусство
- Комедии
- Красота, мода
- Кулинария, рецепты
- Люди
- Мото
- Музыка
- Мультфильмы
- Наука, технологии
- Новости
- Образование
- Политика
- Праздники
- Приколы
- Природа
- Происшествия
- Путешествия
- Развлечения
- Ржач
- Семья
- Сериалы
- Спорт
- Стиль жизни
- ТВ передачи
- Танцы
- Технологии
- Товары
- Ужасы
- Фильмы
- Шоу-бизнес
- Юмор
Should we split first or scale first?? | Data Preprocessing | EDA | Machine Learning.
I do Free Lancing Projects and Final Year Engineering Projects
I even take classes - Machine Learning/Data Science/Fundaments of Python
Contact me on Whatsapp : 9403027341
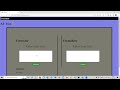
You first need to split the data into training and test set (validation set could be useful too).
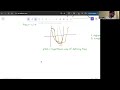
Don't forget that testing data points represent real-world data. Feature normalization (or data standardization) of the explanatory (or predictor) variables is a technique used to center and normalise the data by subtracting the mean and dividing by the variance. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory variables (i.e. the mean and variance).
Therefore, you should perform feature normalisation over the training data. Then perform normalisation on testing instances as well, but this time using the mean and variance of training explanatory variables. In this way, we can test and evaluate whether our model can generalize well to new, unseen data points.
Видео Should we split first or scale first?? | Data Preprocessing | EDA | Machine Learning. канала Stats_With_Sakhala_ji
I even take classes - Machine Learning/Data Science/Fundaments of Python
Contact me on Whatsapp : 9403027341
You first need to split the data into training and test set (validation set could be useful too).
Don't forget that testing data points represent real-world data. Feature normalization (or data standardization) of the explanatory (or predictor) variables is a technique used to center and normalise the data by subtracting the mean and dividing by the variance. If you take the mean and variance of the whole dataset you'll be introducing future information into the training explanatory variables (i.e. the mean and variance).
Therefore, you should perform feature normalisation over the training data. Then perform normalisation on testing instances as well, but this time using the mean and variance of training explanatory variables. In this way, we can test and evaluate whether our model can generalize well to new, unseen data points.
Видео Should we split first or scale first?? | Data Preprocessing | EDA | Machine Learning. канала Stats_With_Sakhala_ji
Комментарии отсутствуют
Информация о видео
6 сентября 2023 г. 22:11:08
00:04:03
Другие видео канала